[+/-]
MySQL 5.1.6 以前のバージョンは、asynchronous replication、単に 「replication」 とよく呼ばれているものは、MySQL Cluster を使用した場合は利用できませんでした。MySQL 5.1.6 では MySQL Cluster のデータベースにマスタースレーブのレプリケーションを導入しています。この項では設定方法および設定の管理について説明します。そこでは MySQL Cluster として運用されている 1 つのグループのコンピュータを 2 番目コンピュータあるいは グループのコンピュータにレプリケートします。標準の MySQL レプリケーションに関しては読者の中にはこのマニュアルのどこかで説明した内容をご存知の方もおられると思います。(章 5. レプリケーション 参照。)
通常 (非クラスタ) のレプリケーションは
「master」 サーバーおよび 「slave」
を、マスタは運用のソースとして、データはレプリケートされるものとして、スレーブはこれらの受皿として含まれています。MySQL
Cluster
では、レプリケーションは概念的には非常に類似していますが、2
つの完全なクラスタ間のレプリケーションを含む多くの異なる設定をカバーするために拡張できるなど実際の運用においてはさらに複雑にできます。MySQL
Cluster そのものは NDB Cluster
ストレージ
エンジンにそのクラスタ機能を依存していますが、スレーブのクラスタ
ストレージ
エンジンを使用する必要はありません。しかしながら、最大の可用性を引き出すために、1
つの MySQL Cluster
から別へレプリケートでき、これが以下の図に示すここで説明する設定タイプです。
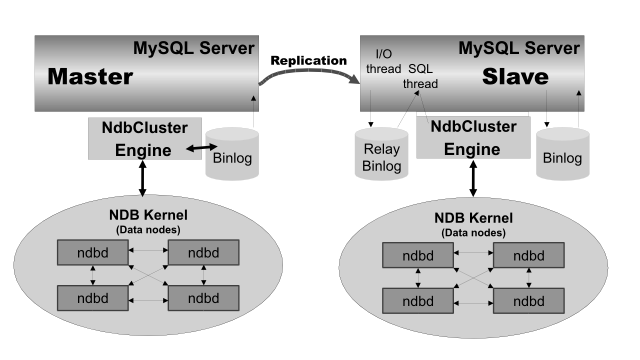
このシナリオでは、レプリケーション
プロセスはマスタ
クラスタの連続的なステートがログされスレーブのクラスタに保存されます。このプロセスは
NDB binlog
インジェクタースレッドとして知られる特別なスレッドによって実現され、それは書く
MySQL サーバー上で動作しバイナリのログ
(binlog)
を生成します。このスレッドはクラスタのすべての変更がバイナリのログ
— を生成し、MySQL Server —
によって影響を受けたそれらの変更だけではなく正確なシリアル番号準にログに挿入されることを確認します。ここでは
MySQL レプリケーション
マスタおよびレプリケーション
サーバーとしてのレプリケーション
スレーブあるいはレプリケーション
ノード、およびそのデータ フローあるいは
replication channel
としてのそれらの間の通信ラインについて言及します。